Server Side Load Balancing
HTTP server load balancing is a simple HTTP request/response architecture for HTTP traffic. But a TCP load balancer is for applications that do not speak HTTP. TCP load balancing can be implemented at layer 4 or at layer 7. An HTTP load balancer is a reverse proxy that can perform extra actions on HTTPS traffic.
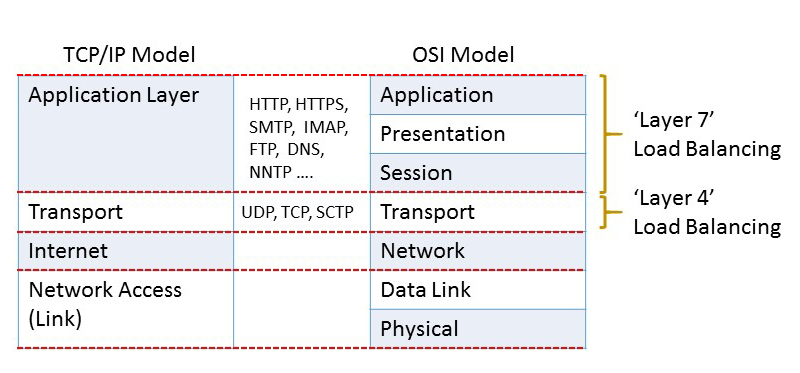
At Layer 4, a load balancer has visibility on network information such as application ports and protocol (TCP/UDP). The load balancer delivers traffic by combining this limited network information with a load balancing algorithm such as round-robin and by calculating the best destination server based on least connections or server response times.
At Layer 7, a load balancer has application awareness and can use this additional application information to make more complex and informed load balancing decisions. With a protocol such as HTTP, a load balancer can uniquely identify client sessions based on cookies and use this information to deliver all a clients requests to the same server. This server persistence using cookies can be based on the server’s cookie or by active cookie injection where a load balancer cookie is inserted into the connection. Free LoadMaster includes cookie injection as one of many methods of ensuring session persistence.
Layer 7 Persistence Methods
Server Cookie Persistence
Server Cookie persistence uses server generated cookies to establish the server to send users to. This method is sometimes referred to as “passive cookie”, as the load balancer only observes the cookie in the HTTP stream.
Active Cookie Persistence
The Active Cookie method is a Layer 7 feature that uses cookies generated by the load balancer, not the server. When a connection is established, the load balancer looks for an active cookie and if that cookie is not there, inserts it into the HTTP stream. Existing server and application cookies are not impacted.
Server Cookie with Source IP Persistence
If the expected server cookies aren’t present (e.g. if a browser is set to refuse cookies), then the source IP address will be used to determine persistence.
Active Cookie with Source IP Persistence
In this case if the expected Active cookies are not present, then the source IP address will be used to determine persistence.
Hash All Cookies Persistence
The ‘Hash All Cookies’ method creates a hash of all cookies in the HTTP stream. This calculated has is used to uniqiely identify client sessions and maintain persistence.
Hash All Cookies with Source IP Persistence
Hash All Cookies or Source IP is identical to Hash All Cookies, with the additional feature that it will fall back to Source IP persistence in the event that no cookies are in the HTTP string.
Source IP Address Persistence
Source IP Address persistence uses the source IP address of the client request to uniquely identify users. This is the simplest method of persistence, and works for all TCP protocols, including those that are not HTTP related. Source IP addess persistent can fail if multiple clients are coming from the same IP address as would be the case of multiple remote clients being behind a NAT device.
Super HTTP
Super HTTP is the recommended method for achieving persistence for HTTP and HTTPS services with LoadMaster load balancers. It creates a fingerprint based on the combined values of the User-Agent field and, if present, the Authorization header.
Client Side Load Balancing
- Netflix Ribbon (old)
- Spring cloud LB, with Eureka naming server for start
- API Gateway ??
Dynamic load balancing algorithms
- Least connection: Checks which servers have the fewest connections open at the time and sends traffic to those servers. This assumes all connections require roughly equal processing power.
- Weighted least connection: Gives administrators the ability to assign different weights to each server, assuming that some servers can handle more connections than others.
- Weighted response time: Averages the response time of each server, and combines that with the number of connections each server has open to determine where to send traffic. By sending traffic to the servers with the quickest response time, the algorithm ensures faster service for users.
- Resource-based: Distributes load based on what resources each server has available at the time. Specialized software (called an "agent") running on each server measures that server's available CPU and memory, and the load balancer queries the agent before distributing traffic to that server.
Static load balancing algorithms
- Round robin: Round robin load balancing distributes traffic to a list of servers in rotation using the Domain Name System (DNS). An authoritative nameserver will have a list of different A records for a domain and provides a different one in response to each DNS query.
- Weighted round robin: Allows an administrator to assign different weights to each server. Servers deemed able to handle more traffic will receive slightly more. Weighting can be configured within DNS records.
- IP hash: Combines incoming traffic's source and destination IP addresses and uses a mathematical function to convert it into a hash. Based on the hash, the connection is assigned to a specific server.